MemoConductor: Distributed Data Without Tears
Almost all business software, and certainly all SaaS software is built around a centralised database - single source of truth to ensure the data remains consistent. On-device computing requires a locally operating, distributed database to maximise the benefits of scalability, latency, reliability and autonomy. Some consider distributed databases to be novel and somehow less consistent than centralised databases, but in fact they can be every bit as effective. In fact, when built with the right principles, distributed databases can be just as effective, if not more so, by fundamentally changing how we think about data integrity. The secret lies in a concept known as Conflict-free Replicated Data Types (CRDTs) and choosing the right granularity.
Traditional SaaS: Centralised Databases and Optimistic Locking
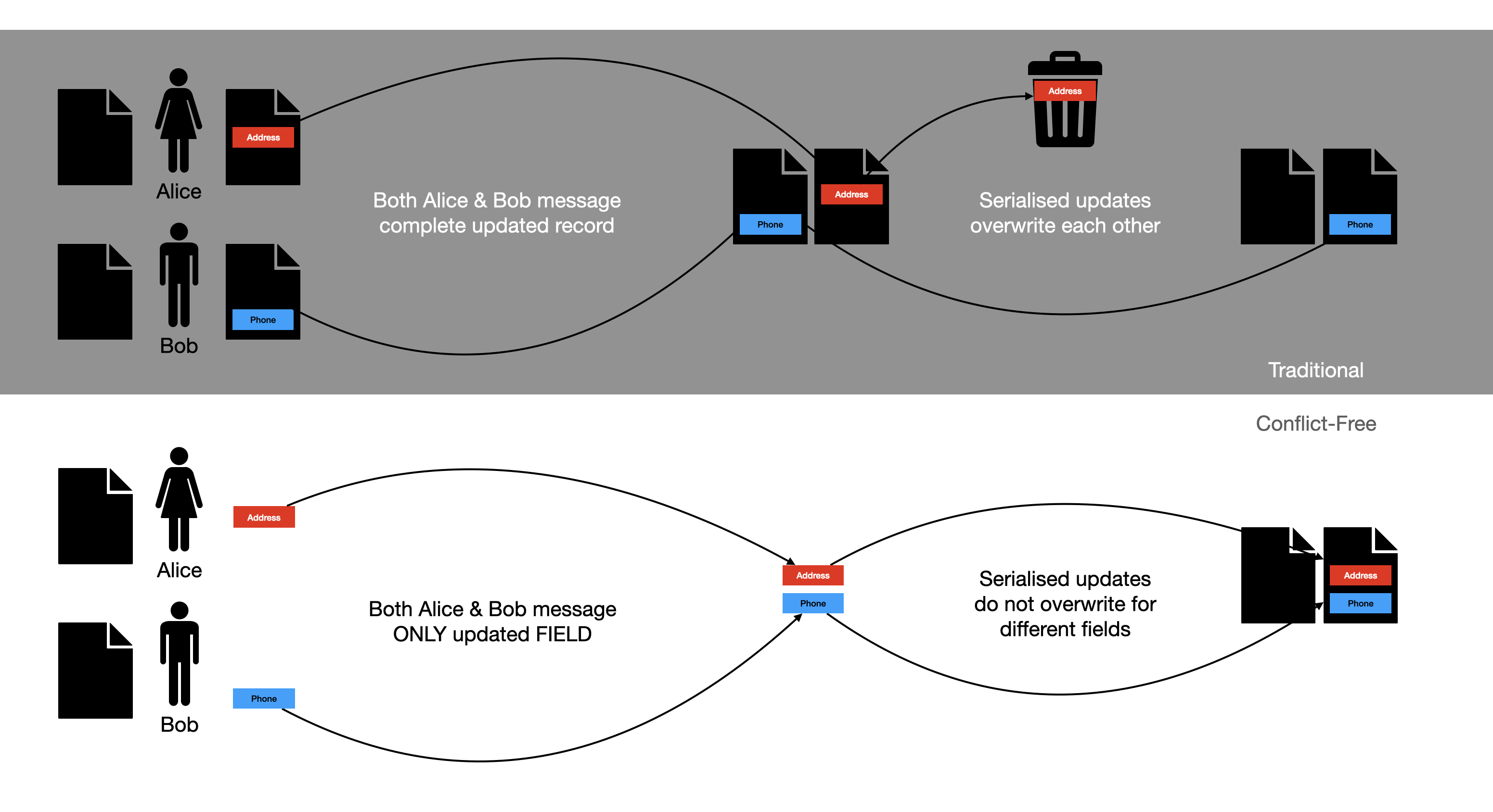
Imagine a classic CRM system. Alice and Bob, two salespeople, want to update a customer's record at the same time. Alice changes the phone number, and Bob changes the email. In a traditional centralised database, this can create issues as both try to access the same record at the same time.
To prevent data loss, the system often uses a strategy called optimistic locking. When Alice and Bob each open the record, they receive a copy with a version number. When Alice saves her change, the system checks to see if the version number is still the same. If so, it updates the record and increments the version. When Bob tries to save his change, the system sees the new version number and rejects his request, forcing him to refresh and try again.
This approach works and ensures data integrity, however, it’s far from perfect. It introduces a frustrating user experience—the classic "this record has been updated by someone else" error. It also creates a single point of failure and a bottleneck for a global user base. The entire world has to wait for a single server to process and commit every transaction.
On-device Computing: Distributed Databases and Messaging
Now, consider a distributed environment. Alice and Bob each work with a local copy of the data on their own devices. The system communicates updates via messages. The old model of a single, authoritative database is gone. Instead, we have many "sources of truth" that need to reconcile their differences. This introduces the problem of eventual consistency. Alice and Bob’s data will be out of sync for a brief period, and the system must have a way to resolve conflicting changes. Naive solutions, like "Last-Write-Wins" based on simple timestamps, can lead to lost data if a clock is out of sync.
Global Clocks: The Impossible Dream
One approach is to try and replicate the behaviour of a centralised system by creating a global distributed clock or sequencer. This is a difficult, if not impossible, problem in practice. While brilliant in principle, these methods often face significant scalability challenges. Lamport timestamps can't distinguish between concurrent events. Vector clocks, while providing a definitive causal order, can incur substantial storage and network overhead in a large system, making them less suited for on-device computing.
CRDTs: Conflict Avoidance by Design
Instead of trying to force a perfect order on a naturally unordered system, a better approach is to use data structures that are designed to be robust to disorder. This is the core idea behind CRDTs. A CRDT is a data type that can be replicated across a distributed network and modified independently, without needing a central coordinator. The real power of this approach comes from applying it at a granular level. Instead of treating the entire customer record as a single object, we can treat each field as its own independent CRDT, and field-level messaging.
When Alice updates the phone number, her local system generates a targeted message: "Update Customer A's phone number to X," with the new data. When Bob updates the email, his system generates a separate message: "Update Customer A's email to Y," with its own new data. Because these two messages are modifying different data fields, they are not in conflict. The distributed system can process both updates and converge on a final record containing both the new phone number and the new email.
This elegant solution provides a number of benefits:
No (Technical) Conflicts
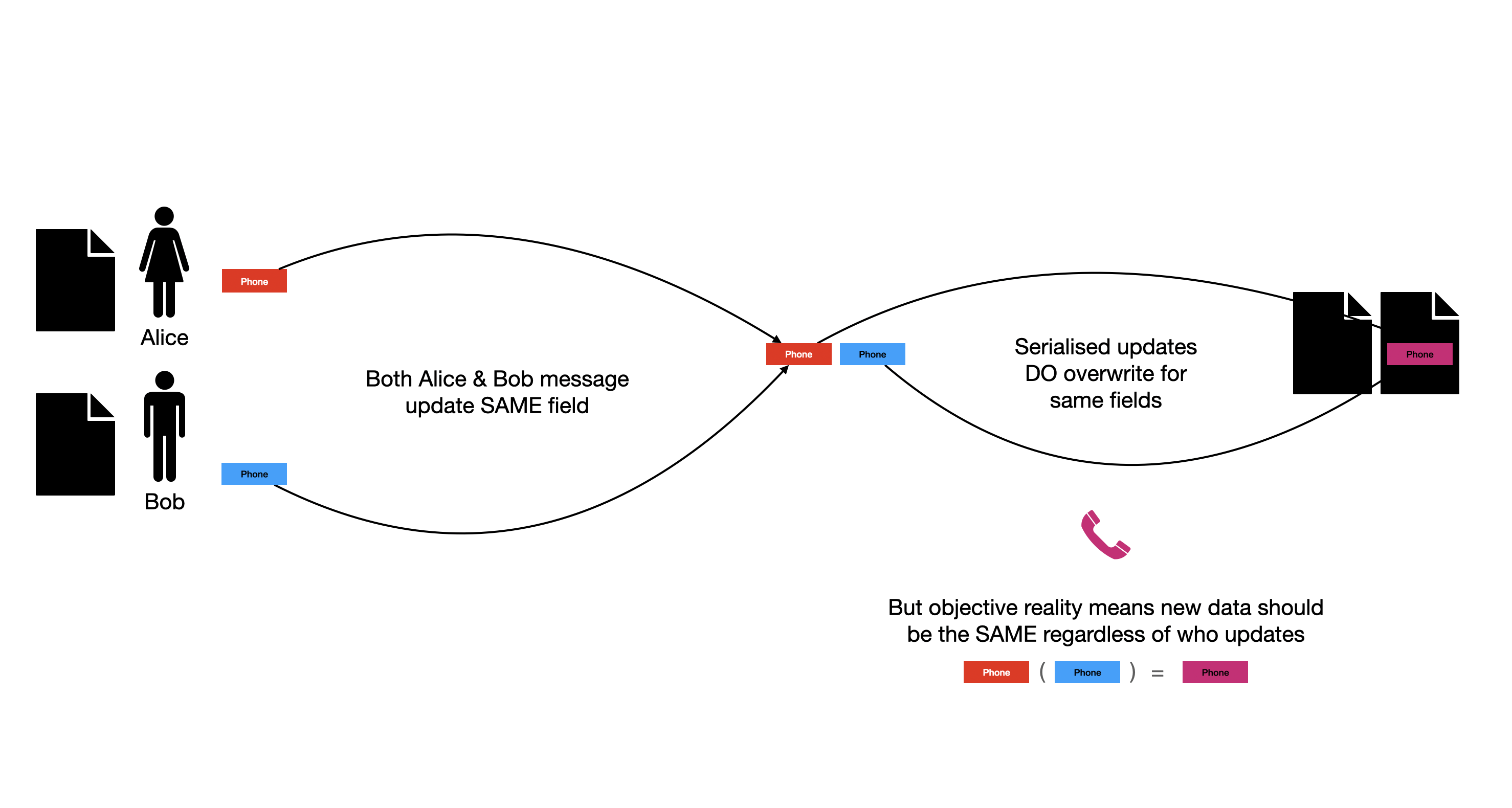
As long as users are editing different fields, there is no need for a complex merge. Both updates are accepted, and the final state is a perfect merge of their changes. When the same field is updated, then either it doesn’t matter, because Alice and Bob are effectively synchronised by the external reality of what the phone number actually is, and will be updating to the same phone number, or they have differing views as to what the number is. If so, then this a business layer problem no technology can solve. A centralised system would be just as vulnerable to Alice and Bob shouting over each other. In these situations, a better approach is to accept multiple data points are valid and explicitly acknowledge multi-valued fields - a common occurrence with both phone numbers and emails.
Offline Access and Low Latency
Users can make changes to their local data instantly, without waiting for network round-trips. The updates are then synchronised with other replicas when connectivity is restored.
High Availability
The system can continue to operate and accept writes even if some nodes are down or disconnected.
Data Sovereignty
You don’t need to ask for your data and no one can cut you off from it.
Concerns about data volumes remain, but modern laptops can comfortably accommodate databases up to 100GB with suitable design. Larger desktop machines can cover terabyte scale if needed.
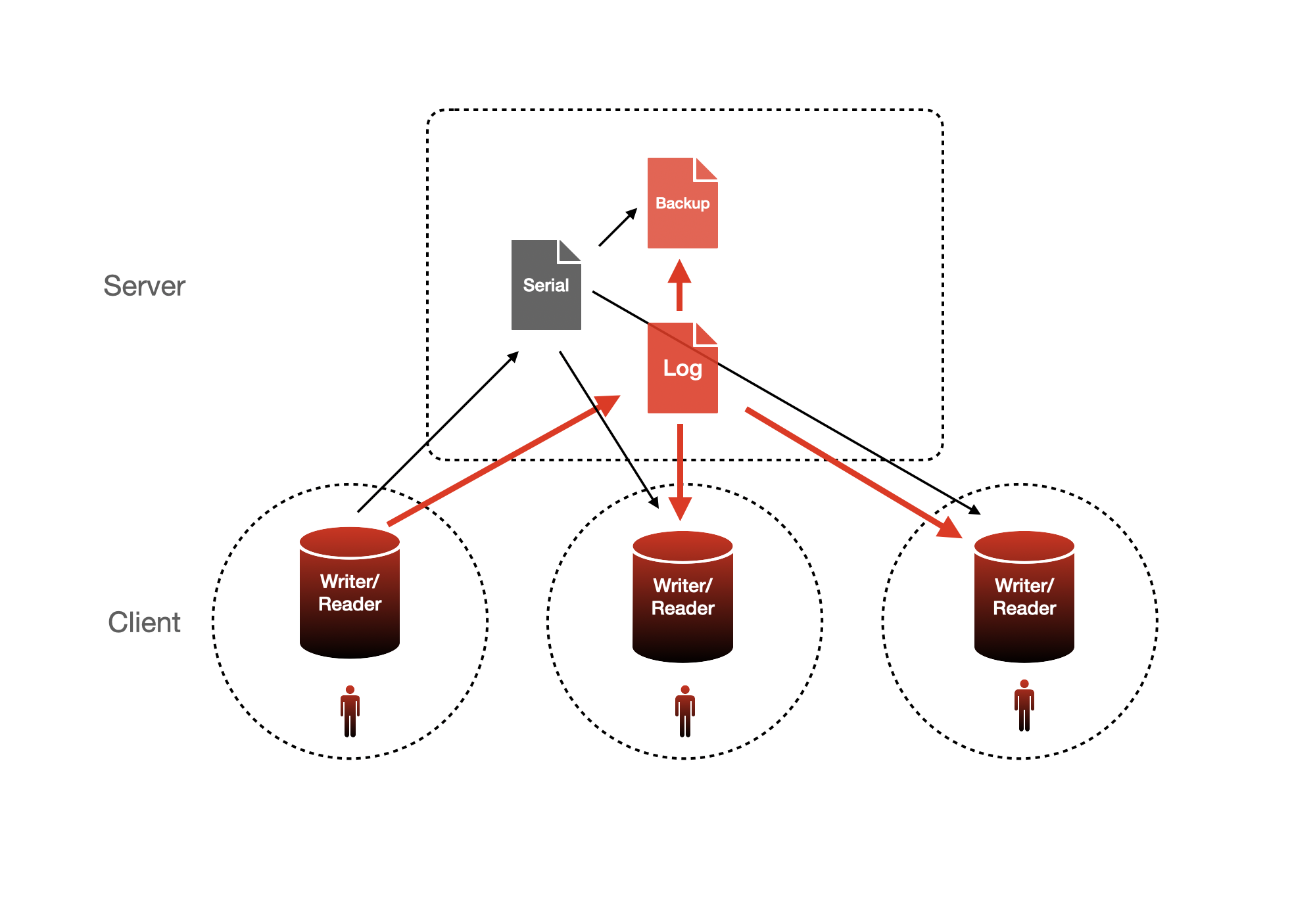
There still remain requirements for strict serialisation, for example, generating an incrementing invoice number. Interestingly, the oft-quoted example of updating an account balance is actually incorrect, as accounting systems treat the journal entry as the transaction, which can be distributed as it is either independent of other journal entries or is synchronised by external reality. The account balance would always be derived data. However, any realistic distributed database must provide a mechanism for some centralised activity, such as a transactional service or a globally-sequenced log, even if for most business systems this is the exception not the norm. MemoConductor supports such serialised data as you would expect.
MemoConductor, a distributed database built upon the principles of field-level CRDTs and a robust messaging system is not a compromise. It is a more accurate and resilient model of our world, which is inherently distributed. By moving from a centralised "single source of truth" to a system that can gracefully merge concurrent, valid truths, we can build the responsive, scalable, and collaborative applications that on-device computing promises.